
Oltre ai token di criptovaluta, la blockchain consente agli analisti di ottenere un quadro più chiaro di qualsiasi progetto di GameFi, NFT, marketplace o protocollo DeFi, grazie a Footprint.
Noi di Footprint abbiamo creato una metodologia che compila e aggrega in modo significativo i dati grezzi della blockchain. E questo vale anche per la programmazione delle integrazioni.
1 . Modi di lavorare con i dati della blockchain
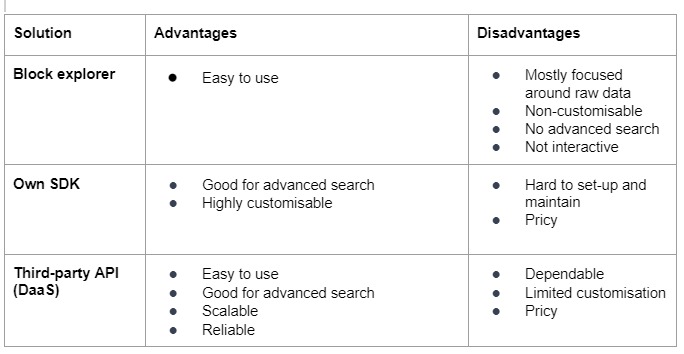
Per prima cosa parliamo dei metodi di integrazione della programmazione. Esistono diversi modi per lavorare con i dati della blockchain e l’approccio scelto dipenderà dalle esigenze e dagli obiettivi specifici. Ecco una rapida panoramica:
1.1 Esploratori della blockchain
Un esploratore di blockchain è un sito web o uno strumento che consente di visualizzare i dati memorizzati su una blockchain. Può essere un modo semplice e veloce per accedere a informazioni su transazioni specifiche, blocchi e altri dati sulla blockchain.
Gli esploratori di blockchain possono essere uno strumento utile per accedere e visualizzare i dati memorizzati su una blockchain, ma presentano alcune limitazioni per le integrazioni software. Ecco alcuni esempi di cose che possono mancare agli esploratori di blockchain:
- Si concentrano principalmente sui dati grezzi. Gli esploratori di blockchain di solito visualizzano i dati grezzi della blockchain. Ciò richiede l’implementazione delle astrazioni sui dati grezzi, il che può essere noioso, soprattutto per i progetti incentrati sulla consegna piuttosto che sui dettagli tecnici di alcune blockchain.
- Opzioni di personalizzazione: Gli explorer di blockchain sono in genere progettati per essere facili da usare, il che significa che potrebbero non offrire molte opzioni di personalizzazione. Questo può rendere difficile adattare l’explorer alle proprie esigenze o preferenze specifiche.
- Funzionalità di ricerca avanzata: Gli esploratori di blockchain spesso dispongono di funzionalità di ricerca di base, ma potrebbero non supportare funzioni di ricerca più avanzate come gli operatori booleani o le espressioni regolari. Questo può rendere difficile la ricerca di informazioni specifiche sulla blockchain.
- Interattività: Molti esploratori di blockchain sono essenzialmente strumenti di sola lettura.
Mentre gli esploratori di blockchain possono essere un modo utile per accedere e visualizzare i dati grezzi della blockchain, presentano alcune limitazioni di cui dovreste essere consapevoli prima di decidere di implementare l’infrastruttura della vostra soluzione basata su di essi.
1.2 Soluzione di indicizzazione propria
Impostare un proprio indicizzatore per lavorare con i dati della blockchain può avere diversi vantaggi e potenziali svantaggi. Ecco alcuni esempi di ciascuno di essi:
Vantaggi:
- Personalizzazione: Quando si imposta l’indicizzatore, si ha il controllo completo sulle modalità di indicizzazione e accesso ai dati. In questo modo è possibile adattare l’indicizzatore alle proprie esigenze e preferenze specifiche.
- Indipendenza: Impostando il proprio indicizzatore, non ci si affida a un servizio di terze parti per la manutenzione e l’aggiornamento dell’indice. Questo può garantire un maggiore controllo e flessibilità nel lavoro con i dati blockchain.
- Migliore sicurezza: Quando si imposta il proprio indicizzatore, è possibile implementare le proprie misure di sicurezza per proteggere i dati e impedire l’accesso non autorizzato.
Svantaggi:
- Complessità: L’impostazione dell’indicizzatore può essere un processo complesso e lungo, soprattutto se si è alle prime armi con la tecnologia blockchain. È necessario comprendere la tecnologia sottostante ed essere disposti a investire il tempo e l’impegno necessari per rendere operativo l’indicizzatore.
- Manutenzione: Una volta configurato l’indicizzatore, sarete responsabili della sua manutenzione e del suo aggiornamento. Ciò può richiedere competenze e risorse tecniche continue, il che può essere uno svantaggio se non si dispone delle conoscenze o del supporto necessari.
- Costo: la creazione di un proprio indicizzatore può essere costosa, in quanto è necessario acquistare l’hardware e il software necessari per il funzionamento dell’indicizzatore e pagare i costi associati, come l’elettricità e la larghezza di banda.
In generale, la creazione di un proprio indicizzatore per lavorare con i dati blockchain può offrire un maggiore controllo e una maggiore personalizzazione, ma può anche essere un processo complesso e costoso. È importante considerare attentamente i vantaggi e gli svantaggi prima di decidere se questo è l’approccio giusto.
1.3 Database come servizio
L’utilizzo di un indicizzatore di terze parti per lavorare con i dati della blockchain può presentare diversi vantaggi e potenziali svantaggi. Ecco alcuni esempi di ciascuno di essi:
Vantaggi:
- Facilità d’uso: Gli indicizzatori di terze parti sono in genere progettati per essere facili da usare, il che significa che si può iniziare a lavorare con i dati della blockchain rapidamente e senza dover imparare molti dettagli tecnici o eseguire la propria soluzione di indicizzazione personalizzata (non importa se è sviluppata in proprio o se è un SDK già pronto).
- Funzionalità di ricerca avanzata: Molti indicizzatori di terze parti offrono funzionalità di ricerca avanzate, come operatori booleani ed espressioni regolari, che facilitano la ricerca di informazioni specifiche sulla blockchain. Le implementazioni possono essere molteplici, ma spesso i dati indicizzati vengono aggiunti a un database relazionale, il che implica il pieno supporto di SQL.
- Scalabilità: Gli indicizzatori di terze parti sono spesso progettati per gestire grandi volumi di dati, il che significa che possono essere una buona opzione se avete bisogno di cercare o accedere ai dati di una blockchain di grandi dimensioni.
- Affidabilità: Gli indicizzatori di terze parti sono in genere gestiti da organizzazioni professionali con le risorse e le competenze necessarie per garantire che l’indice sia sempre aggiornato e accurato. Le soluzioni non sono sempre decentralizzate, poiché si concentrano sull’elaborazione di enormi quantità di dati, ma la maggior parte è open source, il che aumenta la fiducia degli utenti nel servizio.
Svantaggi:
- Dipendenza: Utilizzando un indicizzatore di terze parti, ci si affida a tale servizio per la manutenzione e l’aggiornamento dell’indice. Se l’indicizzatore ha problemi tecnici o va offline, potreste non essere in grado di accedere ai dati della blockchain.
- Personalizzazione limitata: Gli indicizzatori di terze parti sono in genere progettati per essere facili da usare, il che significa che potrebbero non offrire molte opzioni di personalizzazione. Ciò può rendere difficile adattare l’indicizzatore alle vostre esigenze o preferenze specifiche.
- Costo: alcuni indicizzatori di terze parti possono richiedere una tariffa per i loro servizi, il che può essere uno svantaggio se si lavora con un budget limitato.
In sintesi, l’utilizzo di un indicizzatore di terze parti per lavorare con i dati blockchain può essere un’opzione conveniente ed efficace, ma limitata e talvolta priva di personalizzazione.
1.4 Sintesi
L’obiettivo di Footprint è principalmente quello di abbassare la soglia di accesso all’analisi e al lavoro con i dati web3. Questo approccio è un equilibrio tra facilità d’uso e flessibilità. Ecco perché uno dei nostri servizi è DaaS (Database as the service type). Prima di esaminare più da vicino i vantaggi del nostro servizio, esamineremo anche un’altra opzione di implementazione per l’indicizzatore, ovvero una soluzione auto-scritta o SDK.
Nei prossimi capitoli esploreremo la caratteristica principale che le API per blockchain di sola lettura dovrebbero avere. Analizzeremo il problema da diverse angolazioni e prenderemo in considerazione soluzioni alternative. Alcune delle caratteristiche più importanti delle API blockchain sono le seguenti:
- Facilità d’uso e flessibilità
- Scalabilità
- Compatibilità
Facilità d’uso e flessibilità sono due caratteristiche importanti delle API blockchain. Un’API blockchain facile da usare renderà più semplice per gli sviluppatori iniziare a costruire applicazioni basate su blockchain, consentendo loro di prototipare e testare rapidamente le loro idee senza spendere molto tempo per imparare a usare l’API.
La flessibilità, invece, si riferisce alla capacità di un’API blockchain di supportare un’ampia gamma di casi d’uso e applicazioni. Un’API blockchain flessibile consentirà agli sviluppatori di accedere a diverse parti della blockchain e di creare applicazioni che interagiscono con diversi tipi di smart contract e altre risorse basate sulla blockchain. Ciò può essere particolarmente importante per gli sviluppatori che desiderano creare applicazioni utilizzabili in vari settori e contesti.
In generale, disporre di un’API blockchain che sia facile da usare e flessibile può facilitare agli sviluppatori la creazione di applicazioni innovative e utili che possano sfruttare le caratteristiche e le capacità uniche della tecnologia blockchain.
1.5 Analisi dell’impronta
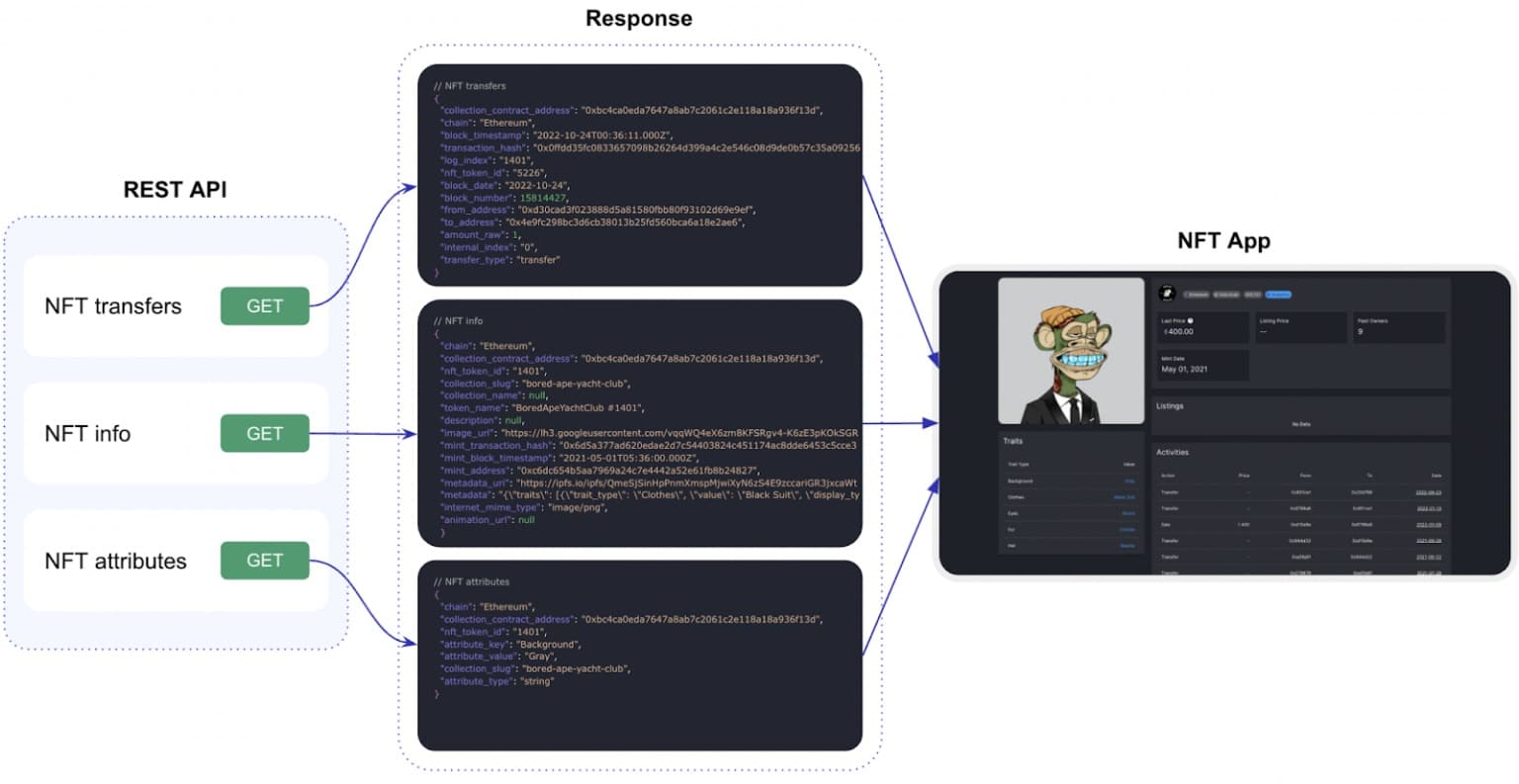
La facilità d’uso e la flessibilità sono garantite dalla nostra organizzazione dei dati, che riguarda tutti gli aspetti delle interazioni con l’ecosistema Footprint. Footprint dispone di un’API costruita sulla base di questo modello di dati che consente agli utenti di creare pipeline di dati complete per l’analisi dei dati e le applicazioni di apprendimento automatico. La chiamiamo API dei dati. Supportiamo contemporaneamente due tipi di API e due sottotipi all’interno di uno di essi per coprire la maggior parte dei casi: API Rest e API SQL.
L’API REST ci consente di integrare rapidamente un’applicazione, poiché ogni endpoint è uno script precostituito e codificato, che abbiamo identificato come uno dei più popolari. Tutti gli endpoint sono dotati di strumenti di facile utilizzo per il filtraggio, l’ordinamento e la paginazione.
Grazie all’interfaccia più adattabile dell’API SQL, è possibile ottenere questo risultato per casi più specifici. Un vantaggio dell’uso delle stesse query SQL sia nell’applicazione web che nell’API è che può semplificare lo sviluppo e la manutenzione. Utilizzando le stesse query in entrambe le interfacce, gli sviluppatori possono evitare di dover scrivere e mantenere serie separate di query per l’applicazione web e per l’API. Ciò consente di risparmiare tempo e fatica e di ridurre il rischio di errori o incoerenze tra le due interfacce.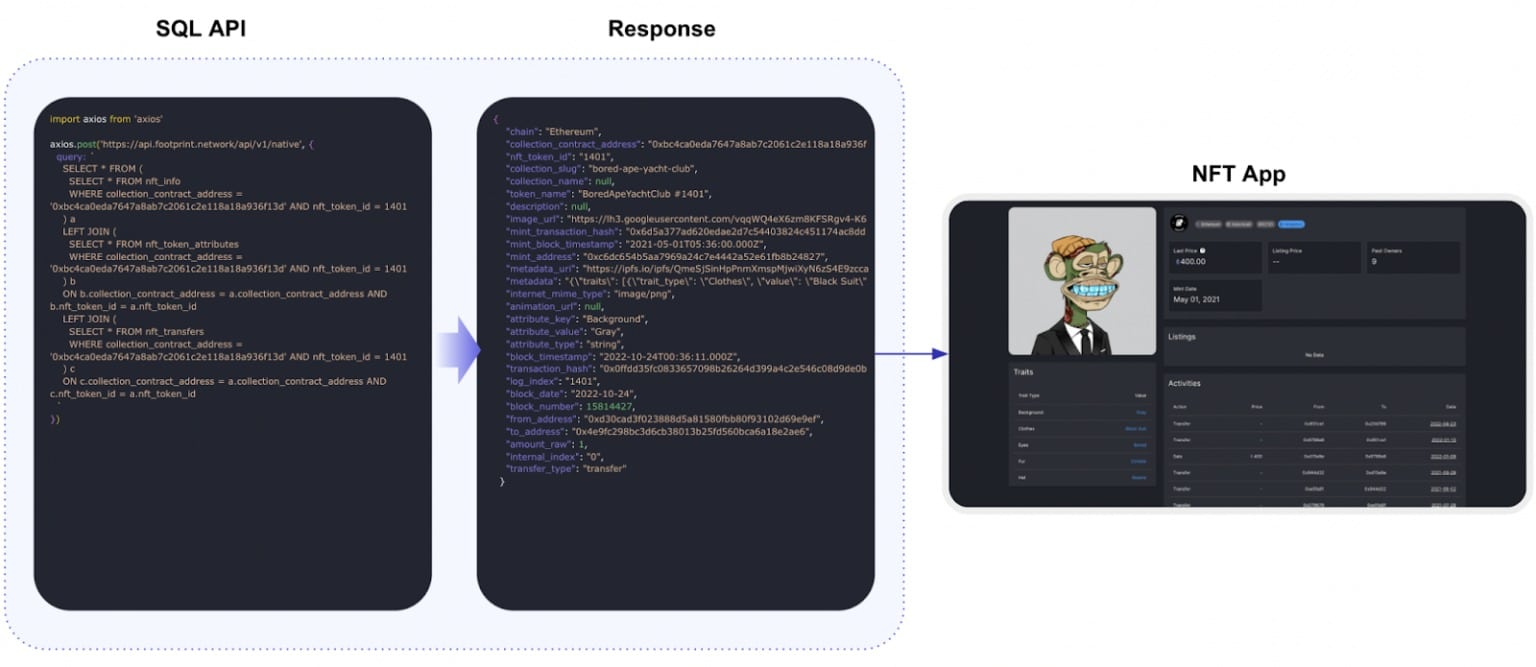
Inoltre, l’uso delle stesse query SQL sia nell’applicazione web che nell’API può facilitare agli sviluppatori la creazione di un’esperienza utente senza soluzione di continuità. Utilizzando le stesse query, gli sviluppatori possono garantire che i dati a cui accedono e che vengono manipolati dall’applicazione web e dall’API siano coerenti, consentendo agli utenti di passare da un’interfaccia all’altra senza incongruenze o interruzioni.
1.6 Altre piattaforme
Molte soluzioni analitiche alternative consentono all’utente di analizzare reti diverse in base a vari livelli di requisiti. Tuttavia, per la maggior parte, le soluzioni alternative tendono a spingersi agli estremi, implementando un prodotto molto flessibile che richiede la conoscenza di linguaggi di interrogazione o addirittura di programmazione, oppure un’interfaccia molto semplice con script preparati e, di conseguenza, una scarsa flessibilità.
Soluzioni come Moralis e Quicknode hanno solo un’interfaccia API REST. Anche se ci sono molti endpoint, questo limita lo sviluppatore nella flessibilità dei dati restituiti.
Dune ha recentemente introdotto la sua API. Questa soluzione asincrona implica l’esistenza preliminare di una query sulla piattaforma con un certo id (dune.com/query/{{query id}}), attraverso la quale è possibile eseguire query in forma di SQL. Il limite principale di questa soluzione è la necessità di pre-modificare l’SQL sulla piattaforma in modo che la query aggiornata venga successivamente eseguita.
Chainbase rilascia API SQL allo stesso modo di Footprint. Tuttavia, a differenza di Footprint, Chainbase non dispone di un ETL così sofisticato, quindi le query SQL possono essere eseguite solo per le transazioni grezze.
2. Scalabilità
Le API per le blockchain dovrebbero essere in grado di gestire grandi volumi di dati e transazioni, consentendo agli sviluppatori di creare applicazioni che possono essere utilizzate da molti utenti contemporaneamente.
2.1 Analisi dell’impronta
2.1.1 Moderno stack di dati aperti
Il team di Footprint ha effettuato diversi aggiornamenti architetturali dal suo lancio nell’agosto 2021, grazie alla sua forte capacità di esplorare e iterare sulla tecnologia. In meno di un anno e mezzo, il team è riuscito a implementare con successo questi cambiamenti. Questo testimonia l’abilità e la competenza del team in materia di tecnologia e scienza dei dati.
Attraverso la sperimentazione, Footprint ha apportato iterativamente tre aggiornamenti architetturali globali, arrivando infine a un’architettura che soddisfa i requisiti dei vari casi d’uso della piattaforma. Maggiori informazioni sull’evoluzione dell’implementazione sono disponibili nel prossimo articolo:
https://www.footprint.network/article/iceberg-spark-trino-a-modern-opensource-data-stack-for-blockchain-fp-HGZpPm3D
2.1.2 Esecuzioni sincrone e asincrone
In Footprint esistono due modalità di esecuzione delle query all’API SQL: sincrona e asincrona. Le chiamate API all’endpoint sincrono implicano che la query SQL venga eseguita dai server Footprint non appena viene ricevuta una richiesta HTTP dall’applicazione, mantenendo così la connessione. Questo ha senso quando si utilizzano richieste leggere, poiché in questo caso l’applicazione non deve attendere a lungo per l’esecuzione. I dettagli sono disponibili alla pagina seguente:
https://docs.footprint.network/reference/post_native
Per le richieste pesanti, si consiglia di utilizzare una richiesta asincrona. A differenza di una richiesta sincrona, l’applicazione client non deve mantenere una connessione con il server durante l’esecuzione. Invece, può ottenere immediatamente il request-id, in base al quale, dopo un certo tempo, ottiene separatamente i risultati dell’esecuzione. Nell’ambito dell’API asincrona, è necessario prevedere due fasi per recuperare i dati: il seguente endpoint sarà utilizzato per inviare un “ordine” per l’esecuzione SQL:
https://docs.footprint.network/reference/post_native-async
Il secondo passo consiste nell’inviare una richiesta per ricevere i risultati in base all’identificatore ottenuto accedendo all’endpoint precedente. L’endpoint per questo secondo passo è descritto nella pagina seguente:
https://docs.footprint.network/reference/get_native-execution-id-results
2.2 Altre soluzioni
DuneV2 cambia l’intera architettura del database. Dune sta passando da un database PostgreSQL a un’istanza di [[Apache Spark]] ospitata su [[Databricks]]. Solo API asincrone.
3. Compatibilità
Le API per le blockchain dovrebbero essere compatibili con un’ampia gamma di linguaggi di programmazione e ambienti di sviluppo, in modo che gli sviluppatori possano utilizzare gli strumenti e i framework con cui hanno maggiore familiarità.
REST è più facile da integrare, poiché ogni linguaggio di programmazione dispone di molte librerie che consentono di lavorare comodamente con questo tipo di API. Tuttavia, alla fine, sia le API SQL che REST funzionano su HTTP, quindi l’esperienza di sviluppo è quasi identica per quanto riguarda l’invio di una richiesta per default.
4. Sintesi
Come abbiamo analizzato, nella maggior parte dei casi è sufficiente che un’applicazione utilizzi soluzioni DaaS già pronte per il motivo che sono in grado di restituire astrazioni (non solo dati grezzi) e di far risparmiare molto tempo e denaro, in quanto consentono ai team di concentrarsi non sull’infrastruttura ma sul valore del prodotto. Esaminando le varie soluzioni presenti sul mercato DaaS,
Footprint sembra essere la più ottimale da integrare, in quanto presenta il modello più flessibile per la generazione delle richieste, oltre a essere facile da usare e ad avere sotto il cofano il moderno stack di dati open-source, che garantisce un’esecuzione ininterrotta e, soprattutto, veloce delle richieste più complesse.