
华为在上周举行的GITEX GLOBAL 2023展会上发布了全新人工智能(AI)存储机型OceanStor A310,尝试解决围绕大型模型应用的一些行业挑战。OceanStor A310专为大型人工智能模型时代而设计,旨在为基础模型训练、行业模型训练和分段场景模型推理提供存储解决方案。
想象一下,OceanStor A310 就像庞大数字图书馆中效率超高的图书管理员,可以快速获取信息碎片。相比之下,另一个系统–IBM的ESS 3500–是一个速度较慢的图书管理员。OceanStor A310获取信息的速度越快,人工智能应用就能越快地工作,及时做出明智的决策。这种快速获取信息的能力使华为的 OceanStor A310 脱颖而出。
OceanStor A310 的优势似乎在于它能够加快人工智能的数据处理速度。据报道,与 IBM 的 ESS 3500 相比,华为最新的全闪存阵列为 Nvidia GPU 供电的速度在每个机架单位的基础上几乎快了四倍。这是根据使用 Nvidia Magnum GPU Direct 的方法计算的,其中数据直接从 NVMe 存储资源发送到 GPU,而不涉及存储主机系统。
华为的 OceanStor A310 展示了高达 400GBps 的连续读取带宽和 208GBps 的写入带宽。不过,开源和闭源框架对这些数据的影响仍不清楚。
深入研究其机制,OceanStor A310 被设计为深度学习数据湖存储解决方案,可为混合工作负载提供无限的横向扩展能力和高性能。
“我们知道,对于人工智能应用来说,最大的挑战是提高人工智能模型训练的效率。”华为产品管理与营销部的 Evangeline Wang 在科技媒体 Blocks and Files 分享的一份声明中说道。”她补充说:”在人工智能训练过程中,存储系统面临的最大挑战是不断向 CPU、GPU 输送数据。”这就要求存储系统提供最佳性能。”
为了解决这个问题,每台OceanStor最多可支持96个NVMe SSD、处理器和内存缓存。用户最多可集群4096个A310,共享一个支持标准协议的全局文件系统,用于应用程序。OceanStor A310旨在通过SmartNIC和大规模并行设计最大限度地缩短数据传输时间。
“华为的 A310 拥有小型节点,在顺序读取和写入方面总体速度最快,顺序写入/读取带宽分别为 41.6/80GBps 和 IBM 的 30/63GBps”。Block and Files 在一项基准研究中将华为的解决方案与其直接竞争对手进行了比较。
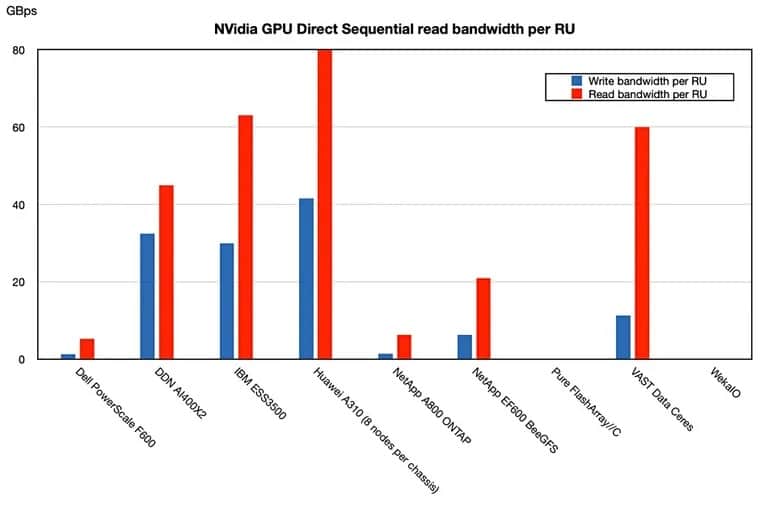
Image: Blocks and Files
OceanStor A310 的发布正值人工智能行业寻求高效数据存储和处理解决方案之际。华为的这一努力旨在应对当前的一些挑战,并可能有助于实现简化的人工智能模型训练。
然而,美国对华为的制裁主要是出于对国家安全的担忧以及该公司被指与中国政府的关系,这为华为进军人工智能存储解决方案领域增加了一层复杂性。
华为 OceanStor A310 的潜在影响可能非常显著。通过为当前数据存储和处理中的一些低效问题提供解决方案,华为正试图挑战其他供应商,并推动人工智能行业走向可能的创新和高效的新时代。